



Solvers
Chameleon
Dense linear algebra
|
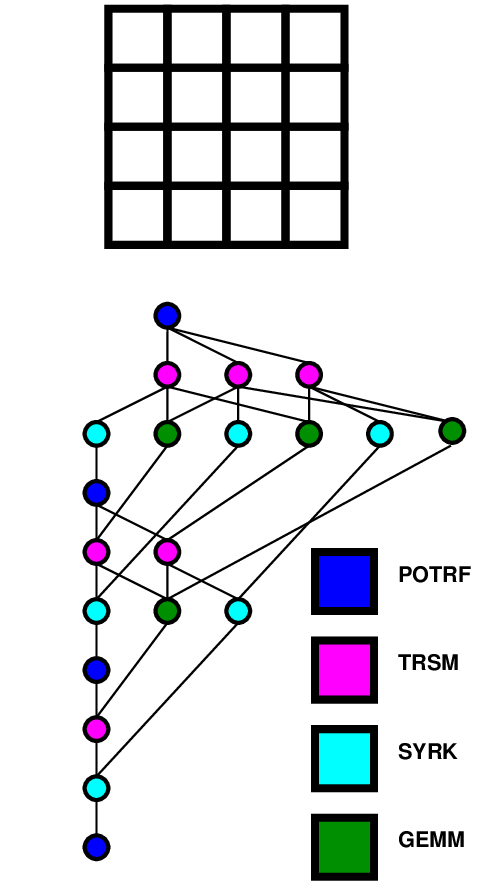
Task-based Cholesky (POTRF) algorithm |
Fmr
Fast Methods for Randomized numerical linear algebra
|
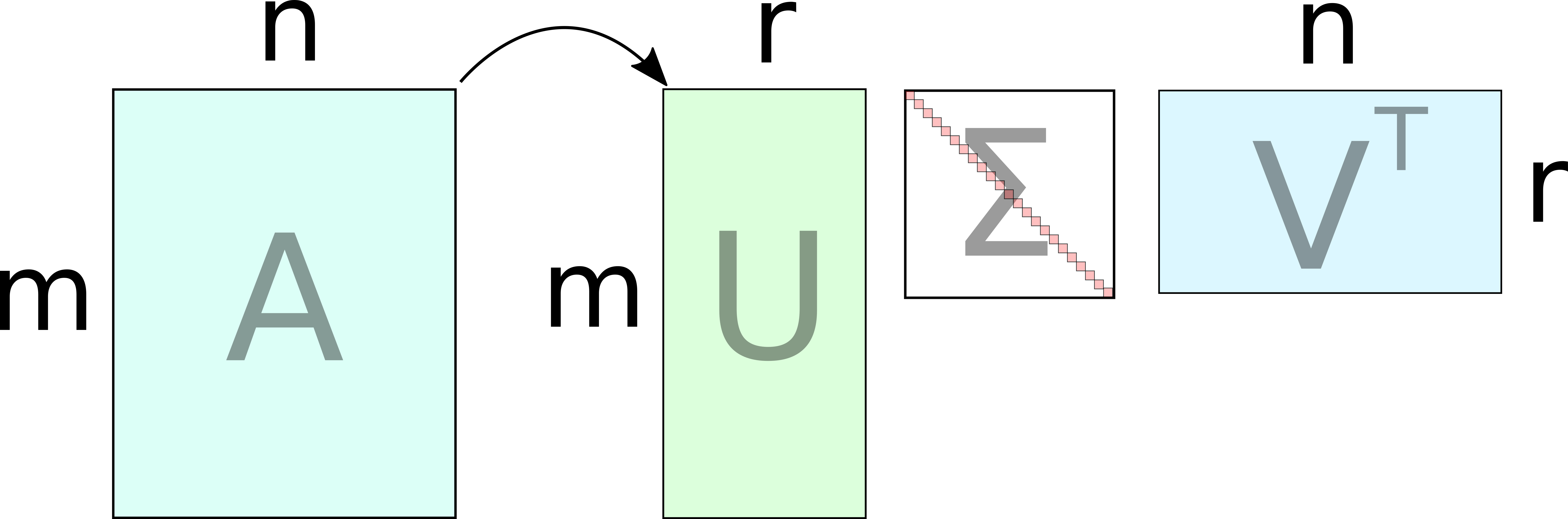
Randomized SVD with a fixed rank r |
Cppdiodon
Parallel C++ library for Multivariate Data Analysis of large datasets
|
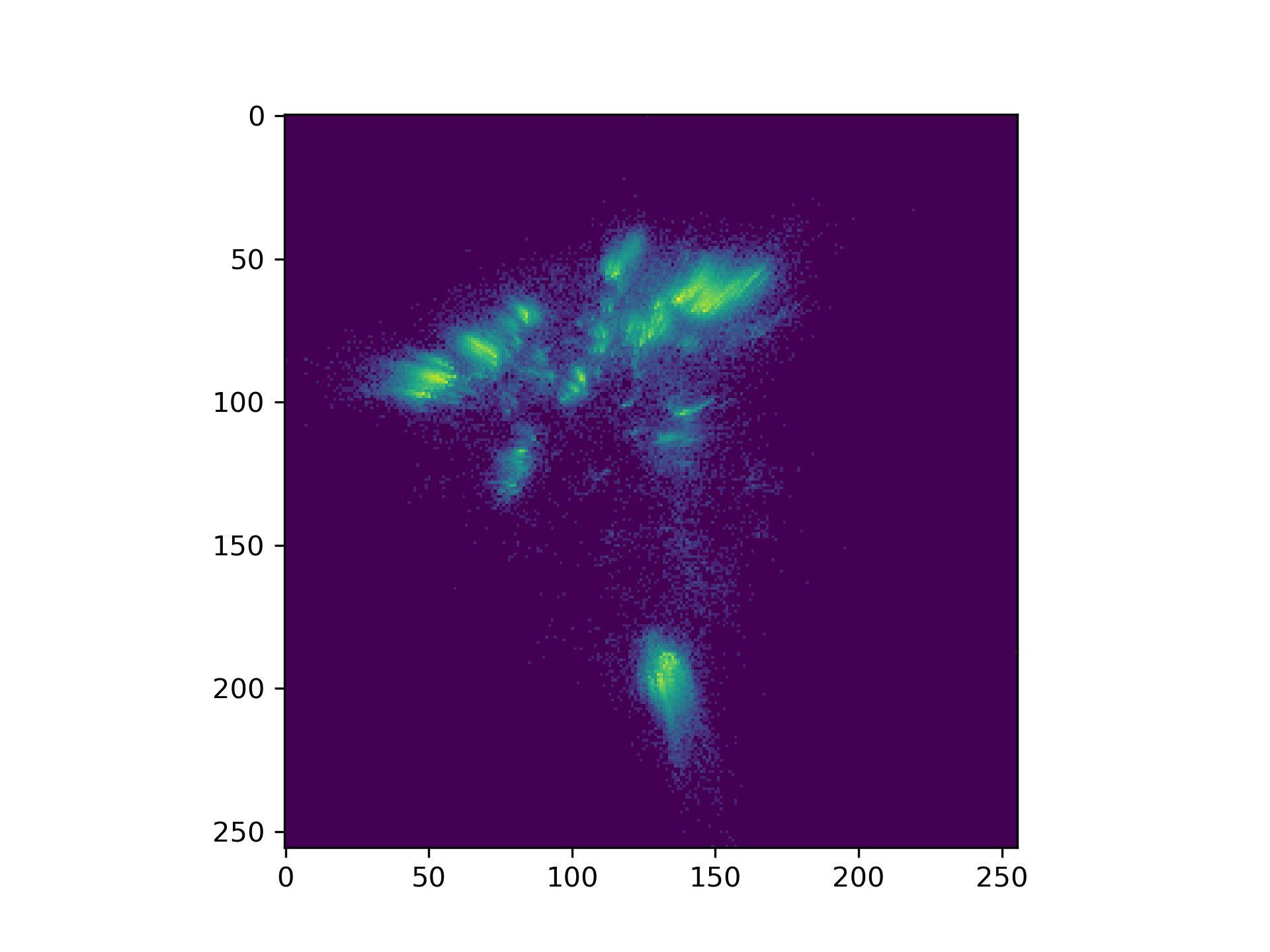
MDS representation on the two first axis |
PaStiX
Sparse linear algebra, supernodal direct solver
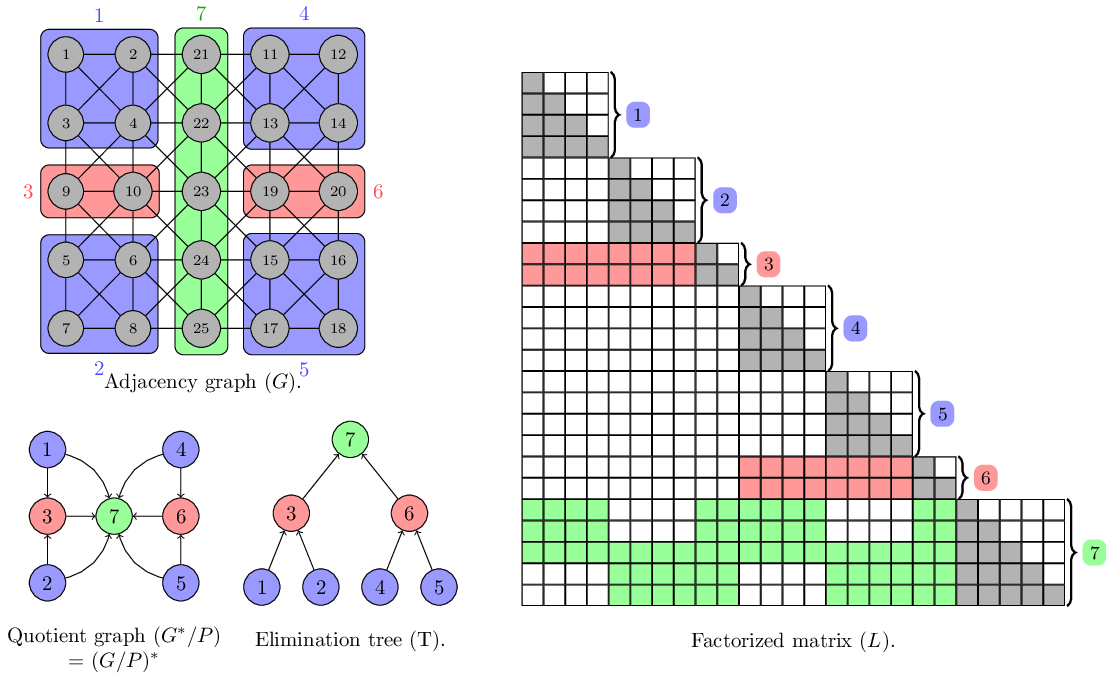
Symbolic factorization |
qr_mumps
Sparse linear algebra, multifrontal direct solver
|
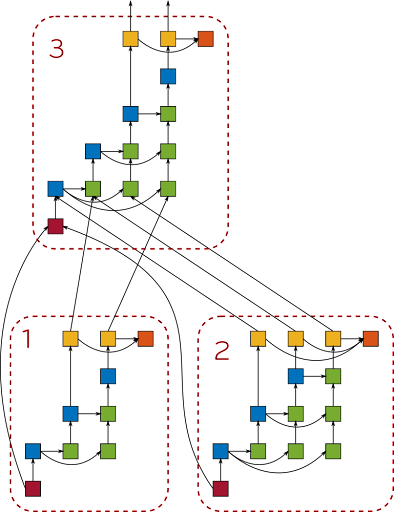
qr_mumps Direct Acyclic Graph |
MaPHyS++
Sparse linear algebra, algebraic domain decomposition
- Written in C++, C and Fortran interfaces, CMake
- Use Direct solvers: MUMPS, PaStiX or qr_mumps
- Use Krylov subspace solver: fabulous
- Use Eigen solver: arpack (preconditioning)
- Matrices forms: general, symmetric
- Storage formats: IJV, armadillo, eigen3
- Precisions: s, d, c, z
- Distributed MPI, hybrid MPI/threads
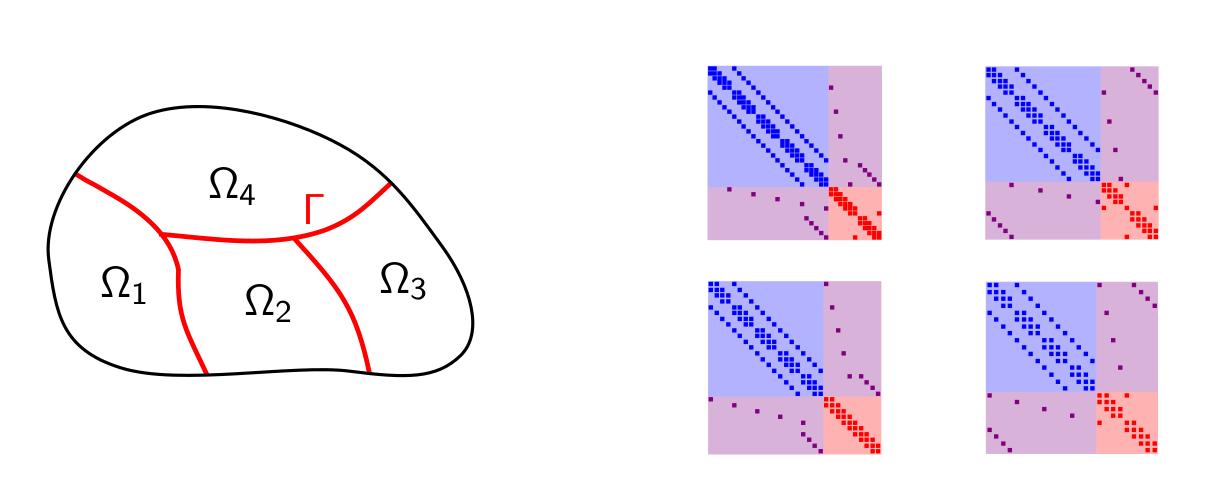
Algebraic domain decomposition |
fabulous
Sparse linear algebra, Block Krylov iterative solver
- Written in C++, C and Fortran interfaces, CMake
- This library currently implements multiple variants of Block
Krylov iterative solvers:
- BCG (Block Conjugate Gradient)
- BF-BCG (Breadown Free BCG)
- BGCR (Block Generalized Conjugate Residual)
- BGMRES (Block General Minimum Residual)
- IB-BGMRES (BGMRES with inexact breakdown)
- BGMRES-DR (BGMRES with deflated restarting)
- IB-BGMRES-DR (BGMRES with inexact breakdown and deflated restarting)
- IB-BGCRO-DR (Block Generalized Conjugate Residual Method with Inner Orthogonalization with inexact breakdown and deflated restarting)
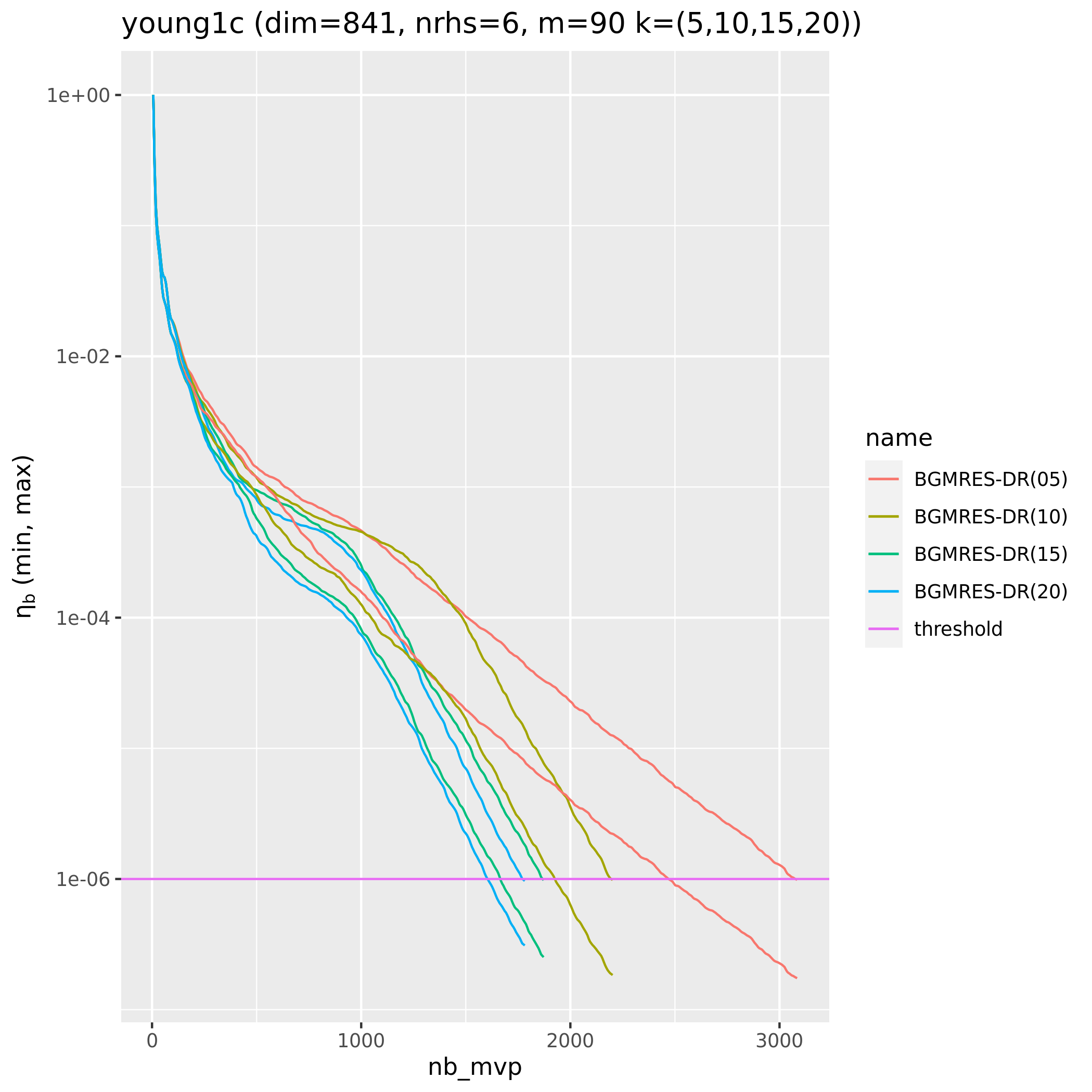
fabulous BGMRES-DR convergence |
StarPU
Runtime system for heterogeneous multicore architectures
|
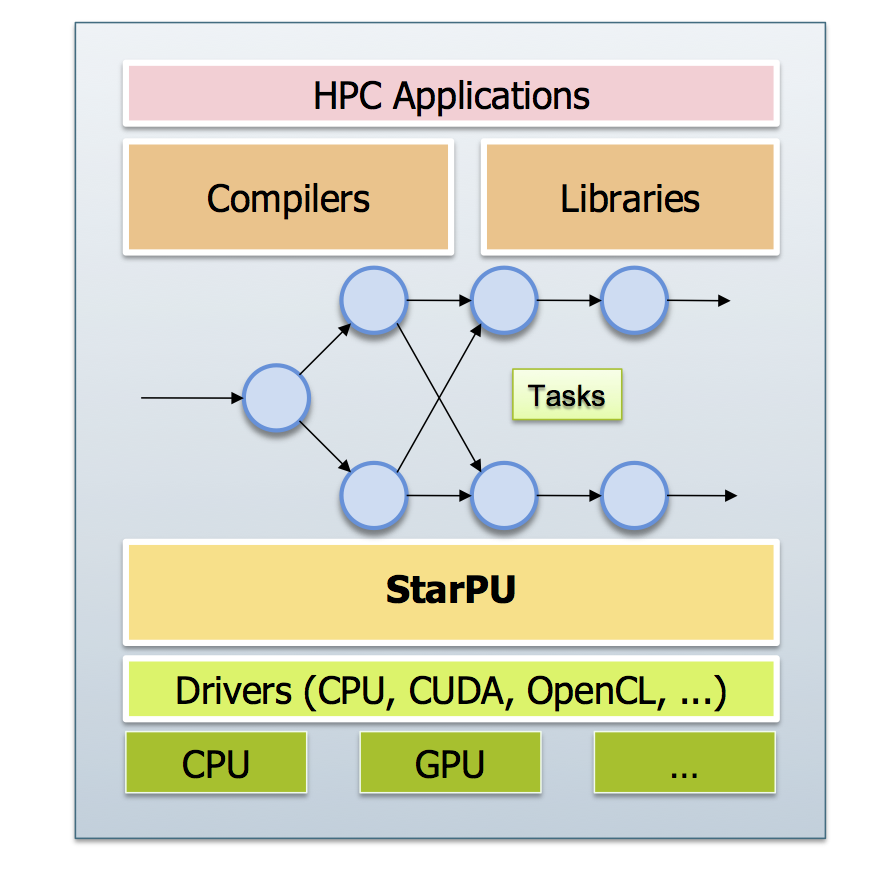
A StarPU overview |
Scotch
Graph partitioning and matrix ordering
- Written in C, Fortran interface, Makefile
- Provides algorithms to partition graph structures, as well as mesh structures defined as node-element bipartite graphs and which can also represent hypergraphs
- Can map any weighted source graph onto any weighted target graph
- Computes amalgamated block orderings of sparse matrices, for efficient solving using BLAS routines
- Offers extended support for adaptive graphs and meshes through the handling of disjoint edge arrays
- Running time is linear in the number of edges of the source graph, and logarithmic in the number of vertices of the target graph for mapping computations
- Distributed MPI (PT-Scotch)

Graph partitioning of a car |